Electronique Mag - Le journal de l'électronique.
- accueil .
- abonnement .
- newsletter .
 Flux RSS .
Flux RSS . - soumissions .
- publicité .
- contacts
Flux RSS .
 L’augmentation régulière des exigences de performances en temps réel de ces applications oblige les développeurs à adopter une approche stratégique pour apporter une réponse appropriée. Compte tenu des performances significatives offertes par de nombreux systèmes sur puce (SoC : System-on-Chip) de grandes dimensions, il est tentant de confier à ces composants les tâches supplémentaires qui se présentent. Toutefois, il convient de comprendre que faute d’être pris en compte avec soin, la latence et le déterminisme représentent des facteurs susceptibles de soulever rapidement d’importants problèmes de traitement en temps réel. Le présent article explore les problématiques dont les concepteurs doivent tenir compte au moment de faire leur choix entre un système sur puce (SoC) et un processeur de signal numérique (DSP) dédié aux tâches audio, l’objectif étant d’éviter toute mauvaise surprise aux utilisateurs de leur système acoustique en temps réel.
L’augmentation régulière des exigences de performances en temps réel de ces applications oblige les développeurs à adopter une approche stratégique pour apporter une réponse appropriée. Compte tenu des performances significatives offertes par de nombreux systèmes sur puce (SoC : System-on-Chip) de grandes dimensions, il est tentant de confier à ces composants les tâches supplémentaires qui se présentent. Toutefois, il convient de comprendre que faute d’être pris en compte avec soin, la latence et le déterminisme représentent des facteurs susceptibles de soulever rapidement d’importants problèmes de traitement en temps réel. Le présent article explore les problématiques dont les concepteurs doivent tenir compte au moment de faire leur choix entre un système sur puce (SoC) et un processeur de signal numérique (DSP) dédié aux tâches audio, l’objectif étant d’éviter toute mauvaise surprise aux utilisateurs de leur système acoustique en temps réel.
Les systèmes acoustiques à faible latence sont présents dans un large éventail d’applications. C’est notamment le cas du secteur automobile où la latence joue un rôle essentiel dans les zones audio personnelles, la suppression du bruit de roulement ou les systèmes de communications embarqués.
Face à l’électrification croissante des véhicules automobiles, la suppression du bruit de roulement (RNC : Road Noise Cancellation) constitue un enjeu majeur, en l’absence de moteur à combustion générant le bruit habituel. Résultat, les sons associés au roulement du véhicule sur la chaussée deviennent nettement plus perceptibles et gênants. Outre une expérience de conduite plus confortable, la réduction de ce bruit contribue à réduire la fatigue du conducteur. La mise en oeuvre d’un système acoustique à faible latence sur un SoC et non sur un DSP audio dédié soulève de nombreux défis, que ce soit sur le plan de la latence, de l’évolutivité, de la facilité de mise à niveau, du traitement des algorithmes, de l’accélération matérielle ou du support client. Nous allons nous pencher successivement sur ces points. Latence.
Le problème de la latence dans les systèmes de traitement acoustique en temps réel est important. Si le processeur n’est pas en mesure de suivre le mouvement des données en temps réel et de faire face aux besoins de calcul du système, des pertes audio risquent de se produire, ce qui n’est pas acceptable.
De manière générale, les systèmes sur puce embarquent une mémoire SRAM de capacité réduite, de sorte qu’ils doivent compter sur le cache pour gérer la plupart des demandes d’accès à la mémoire locale. Cette contrainte induit une disponibilité non déterministe du code et des données, tout en augmentant la latence du traitement. Dans des applications en temps réel telles que l’annulation active du bruit (ANC), ce facteur peut à lui seul être rédhibitoire, sans oublier le fait que les systèmes sur puce utilisent des systèmes d’exploitation qui ne fonctionnent pas en temps réel et gèrent de lourdes charges en mode multitâches. Cette situation amplifie la caractéristique de fonctionnement non déterministe du système, rendant très délicate la prise en charge d’un traitement acoustique relativement complexe au sein d’un environnement multitâches.
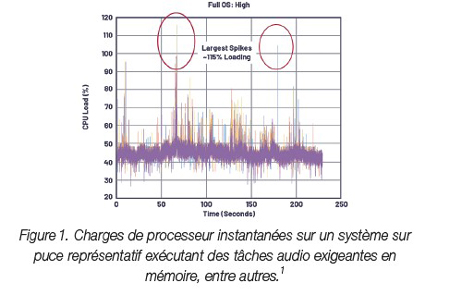
La figure 1 représente un système sur puce exécutant une charge de traitement audio en temps réel, où la charge du processeur (CPU) atteint un pic élevé lorsque des tâches sont traitées en priorité. Ces pics peuvent se produire en raison d’activités sollicitant le système sur puce : rendu multimédia, navigation ou exécution d’applications sur le système, par exemple. Lorsque les pics dépassent 100 % de la charge du processeur, le SoC ne fonctionne plus en temps réel, ce qui provoque des microcoupures audio.
Pour leur part, les DSP audio sont architecturés pour assurer une faible latence tout au long du processus de traitement du signal, de l’entrée audio échantillonnée jusqu’à la sortie composite du haut-parleur (par exemple, audio et antibruit). La mémoire SRAM de premier niveau (L1), chargée des instructions et des données (la mémoire à cycle unique la plus proche du coeur du processeur), est suffisamment puissante pour prendre en charge plusieurs algorithmes de traitement sans basculer les données intermédiaires vers une mémoire externe. Pour sa part, la mémoire L2 embarquée (plus éloignée du coeur du processeur, mais nettement plus rapide d’accès que la DRAM externe) fournit un tampon pour les transactions de données intermédiaires lorsque la capacité de stockage de la mémoire SRAM L1 est atteinte. Enfin, les DSP audio utilisent généralement un système d’exploitation temps réel (RTOS) pour que les données entrantes soient traitées et envoyées à destination avant l’arrivée de nouvelles informations. Cette technique évite que les tampons de données ne débordent lorsque le système opère en temps réel.
La latence effective au démarrage du système souvent mesurée par le délai de disponibilité du son représente elle aussi une métrique importante, notamment dans les systèmes automobiles où il est important que les avertissements sonores soient diffusés dans une certaine fenêtre à partir du démarrage. Dans le domaine des systèmes sur puce, où les longues séquences de démarrage impliquant le lancement du système d’exploitation pour l’ensemble du dispositif ne sont pas rares, il peut s’avérer difficile, sinon impossible de répondre à une telle exigence au démarrage. En revanche, un DSP audio autonome qui exécute son propre système d’exploitation temps réel (RTOS) sans être perturbé par d’autres priorités externes, peut être optimisé pour démarrer rapidement, ce qui répond sans difficulté aux exigences d’activation du son.
Si la latence soulève effectivement des problèmes lorsqu’un système sur puce est utilisé avec des applications telles que le contrôle du niveau de bruit, l’évolutivité pénalise également les SoC chargés de tâches de traitement acoustique. En d’autres termes, les SoC qui contrôlent des systèmes de grandes dimensions (unités de tête de réseau ou clusters de systèmes automobiles) en association avec de nombreux sous-systèmes hétérogènes peuvent difficilement monter en échelle en remplaçant des exigences audio bas de gamme par des performances haut de gamme, en raison du conflit constant entre les exigences d’évolutivité de chaque composant du sous-système. Cet état de fait implique des compromis dans l’utilisation globale des SoC. À titre d’exemple, si un système sur puce destiné à l’unité de tête de réseau (head end unit) se connecte à un syntoniseur distant et si, d’un modèle d’automobile à l’autre, ce système d’accordage doit passer de quelques canaux à plusieurs canaux, chaque configuration de canal amplifiera les problèmes de traitement en temps réel mentionnés ci-dessus. En effet, chaque fonction supplémentaire pilotée par le SoC modifie le comportement en temps réel du SoC, ainsi que la disponibilité en ressources des composants architecturaux utilisés par différentes fonctions bande passante mémoire, cycles du coeur de processeur ou le processus d’arbitrage de la structure du bus système.
Outre le problème soulevé par la connexion d’autres sous-systèmes au SoC multitâches, le sous-système acoustique n’est pas exempt de problèmes d’évolutivité, qu’il s’agisse de l’évolution vers une gamme supérieure (par exemple, l’augmentation du nombre de canaux pour les microphones et les haut-parleurs dans une application d’annulation active du bruit) ou le perfectionnement de l’expérience audio, par exemple le remplacement des fonctions élémentaires de décodage audio ou de lecture stéréo par la virtualisation 3D et autres applications de pointe. Si elles ne partagent pas les mêmes contraintes en temps réel que les systèmes ANC, ces exigences pèsent néanmoins directement sur le choix du processeur audio.
L’utilisation d’un DSP séparé en tant que coprocesseur associé à un système sur puce permet de résoudre le problème de l’évolutivité audio tout en bénéficiant d’une conception système modulaire et d’un coût optimisé. En effet, le SoC n’est plus obligé de se concentrer sur les tâches de traitement acoustique en temps réel pour l’ensemble du système, confiant ce traitement au DSP audio à faible latence. De plus, les DSP audio déclinés en plusieurs niveaux de prix/performances/mémoire dans le cadre d’une feuille de route complète offrant une compatibilité totale à la fois au niveau du code et du brochage assurent aux concepteurs système une flexibilité maximale pour adapter les performances audio à la qualité de produit souhaitée.
La mise à jour de micrologiciels par voie hertzienne (OTA : Over The Air) étant de plus en plus fréquente à bord des véhicules automobiles, la possibilité de diffuser des correctifs critiques ou de déployer de nouvelles fonctionnalités revêt une importance croissante. Ce qui n’est pas sans poser des problèmes majeurs s’agissant des systèmes sur puce, en raison notamment des dépendances élevées entre leurs différents sous-systèmes. Sur les SoC tout d’abord, de multiples tâches de traitement et de déplacement de données se disputent les ressources disponibles, augmentant la course à la capacité de calcul (MIPS) du processeur et à la mémoire lorsque de nouvelles fonctionnalités sont ajoutées en particulier lors de pics d’activité. S’agissant des fonctions audio, l’ajout de fonctionnalités dans d’autres domaines de contrôle du SoC peut avoir un effet imprévisible sur les performances acoustiques en temps réel. Entre autres effets secondaires, les nouvelles fonctionnalités doivent faire l’objet de tests croisés dans les différents plans d’exploitation, avec pour conséquence une myriade de permutations entre les multiples modes opératoires des sous-systèmes en concurrence. Autrement dit, la vérification des logiciels augmente de manière exponentielle à chaque campagne de mises à niveau.
Vu sous un autre angle, il apparaît que l’amélioration des performances audio du SoC dépend de la puissance de calcul (MIPS) dont dispose le SoC, en plus de la feuille de route fonctionnelle des autres sous-systèmes qu’il pilote.
Il apparaît clairement que s’agissant du développement d’algorithmes acoustiques en temps réel, les DSP audio répondent parfaitement aux attentes. Entre autres critères les différenciant des SoC, les DSP audio autonomes proposent un environnement de développement graphique où les ingénieurs disposant d’une expérience minimale en codage de DSP peuvent enrichir leur conception d’un traitement acoustique de haute qualité. Un tel outil permet en outre de réduire les coûts de développement en raccourcissant les délais de développement, sans répercussions sur la qualité ni sur les performances.
À titre d’exemple, l’environnement de développement audio graphique SigmaStudio® d’ADI intègre de nombreux algorithmes de traitement du signal dans une interface graphique (GUI) intuitive, ce qui permet de créer des flots de signaux audio complexes. En prenant également en charge la configuration graphique Automotive Audio Bus (A²B) pour transporter les données audio, cet outil contribue grandement à accélérer le développement de systèmes acoustiques en temps réel.
Outre une architecture de coeur de processeur spécialement conçue pour accéder aux données tout en exécutant efficacement des calculs en virgule flottante, les DSP audio sont souvent dotés d’accélérateurs multicanaux dédiés chargés d’élaborer des primitives audio courantes telles que les transformées de Fourier rapides (FFT), le filtrage à réponse impulsionnelle finie ou infinie (FIR et IIR) et la conversion de fréquence d’échantillonnage asynchrone (ASRC : Asynchronous Sample Rate Conversion). Ces fonctions permettent d’effectuer des opérations de filtrage, d’échantillonnage et de conversion des signaux audio en temps réel dans le domaine fréquentiel en dehors du processeur, ce qui augmente les performances effectives du coeur. En outre, elles permettent de créer un modèle de programmation flexible et convivial grâce à leur architecture optimisée et à leurs capacités de gestion du flot de données.
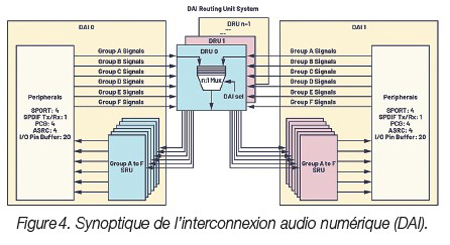
En raison de la prolifération du nombre de canaux audio, des flux de filtrage et de la fréquence d’échantillonnage, il est important de disposer d’une interface de brochage affichant une flexibilité de configuration maximale pour assurer la conversion de la fréquence d’échantillonnage en ligne, d’une fonction de cadencement d’horloge haute précision et de ports série synchrones à haut débit pour acheminer les données efficacement, mais également éviter une latence supplémentaire ou le recours à une logique d’interface externe. L’interconnexion audio numérique (DAI) dont bénéficient les processeurs de la famille SHARC® d’ADI illustre cette capacité, comme le montre la figure 4.
Le support client représente un aspect souvent négligé des stratégies de développement reposant sur un processeur intégré.

Bien que les fournisseurs de SoC encouragent l’exécution d’algorithmes acoustiques sur leurs DSP intégrés, cette approche n’est pas sans induire certains risques concrets. Tout d’abord, l’assistance fournie s’avère souvent complexe, dans la mesure où l’expertise acoustique ne fait généralement pas partie du développement des applications pour SoC. Par conséquent, les clients qui souhaitent développer leurs propres algorithmes acoustiques en utilisant la technologie DSP intégrée au SoC bénéficient généralement d’un soutien limité. En d’autres termes, les fournisseurs risquent de proposer des algorithmes standard et facturer des coûts d’ingénierie non récurrents élevés pour migrer les algorithmes acoustiques sur un ou plusieurs coeurs du SoC. Et même dans ce cas, il n’existe aucune garantie de succès, surtout si le fournisseur ne propose pas de logiciel mature et à faible latence. Enfin, l’écosystème tierce partie de traitement acoustique à base de SoC a tendance à être plutôt fragile, étant donné qu’il ne s’agit pas d’un atout majeur du système sur puce, mais d’une fonctionnalité prise en charge de manière opportuniste.

Il apparaît clairement qu’un DSP spécialement conçu pour les applications audio repose sur un écosystème nettement plus solide pour développer des systèmes acoustiques complexes, qu’il s’agisse des bibliothèques d’algorithmes, des pilotes de périphériques optimisés, des systèmes d’exploitation en temps réel (RTOS) ou des outils de développement d’utilisation aisée. De plus, si les plateformes de référence dédiées aux applications audio (la plateforme audio SHARC d’ADI illustrée à la figure 5, par exemple) et capables d’accélérer la mise sur le marché sont peu nombreuses pour les SoC, elles sont relativement courantes sur le marché des DSP audio autonomes.
Références :
1. Paul Beckmann. “Multicore SOC Processors : Performance, Analysis, and Optimization.” 2017 AES International Conference on Automotive Audio, août 2017.



